Ok, there seems to be a lot of confusion and misinformation floating about this thread. Let me try my best to explain things. First of all, 2D+depth is not a true stereoscopic format. To be considered stereoscopic you will need pictures from 2 (or more) viewpoints in order to reproduce a 3D image in your mind. 2D+depth can be used to produce a stereoscopic image, however it does this using interpolation. This means there is a computer algorithm with scans through every single pixel of the 2D image and adjusts its position in space relative to where it would be in 3D dimensions (based on the grayscale level in the depthmap). This part can actually be done with a good deal of accuracy. What is difficult to do is to figure out what it is that is behind the pixels you have just moved (which now contain empty space, as seen in the Kinect video). To do this you need an algorithm which recreates the information that DOES NOT EXIST in the 2D image. No matter how smart your programmers are or how many super-computers you have, you are not getting this information back. It is like taking a black & white photograph, the color information is lost forever. The only difference is that with 2D+depth it is easier to attempt to extrapolate this missing information. What many programs do, is that they simply stretch the surrounding pixels to fill in the empty space. If the background is a solid color (such as a blue sky) then this works pretty well and is not noticeable. However if the occluded area contains detailed textures, or is so large as to contain entire objects, then this doesn't work very well at all. Again, creating the depth or pop-out is not a problem. Using 2D+depth you can produce stereo images with equivalent depth perception. However, in practice you will have to avoid excessive depth (in either direction) as this causes the flaws in the process to be glaring. I was actually, at one point, working on a 2D+depth image conversion application and I do have a very early version somewhat working. However these limitations of 2D+depth convinced me to abandon the project. Let me illustrate this for you.
This is a sample image I was using for testing:
Here is the depthmap I was using. Notice that the square is popping out of the screen, the bars are at perfect screendepth and the background is inside the screen:
Here is how the stereo side-by-side (cross-eye) image looks without any recreation of the missing pixels:
As you can see, there are large areas that are simply black. We just do not have this information and we cannot get it back. This is not just a problem with "out-of-screen" effects. Any pixel that is moved (meaning every single pixel that is not at screen-depth) will leave a blank space in its wake. This is a fundamental problem with the method and there is only so much you can do to re-create this lost information. This was my early attempt at generating the missing pixels. All it does is simply stretch the surrounding pixels (that are behind it) to fill the space. Its not even a fancy algorithm, but its obviously better than having black areas.
You can see that this method works OK for the background, however it fails pretty bad on the vertical bars, which get pieces of them pulled away by the square in the middle. Of course, a better algorithm could account for this, but it becomes a problem as the scene gets more complex. Since you have to distort the image to fill in the space, you do not want to distort it too much or it will look really bad. You also do not want to double distort (as in recreating pixels from ones you already created in an earlier pass) as this is like copying a VHS tape over and over. This is why they usually lock to depth really low when using this method. If the objects are only shifting a couple of pixels then you will not notice the distortion. If an object moves by a large amount, say more than 100 pixels, then you will notice. Also, this example I am giving is very simple as I am using flat shapes (which is sort of similar to what Neil was saying with the deck of cards). However in a real-world situation the objects would be fully fleshed out with curves and bumps and creases in their cloths. So it is not the case that 2D+depth has to produce a "cardboard-cutout" style of 3D. The individual objects themselves can very well have depth of their own, like the nose on someones face for example. So the deck of cards analogy does not really hold weight. A 2D+depth based algorithm works on a pixel level, and each pixel has its own distinct depth. It has no knowledge of what object is what or what pixel belongs to what object. I hope my explanation makes some sense to you guys as I would like it if we were all on the same page.
I am going to fire up the DDD driver and see if I can capture some screengrabs that will make this more obvious. Then we can settle this for good.
Kinect Inadvertently Demonstrates 3D, U-Decide Update
-
cybereality

- 3D Angel Eyes (Moderator)
- Posts: 11407
- Joined: Sat Apr 12, 2008 8:18 pm
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
You do not have the required permissions to view the files attached to this post.
-
Fredz
- Petrif-Eyed
- Posts: 2255
- Joined: Sat Jan 09, 2010 2:06 pm
- Location: Perpignan, France
- Contact:
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
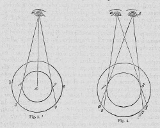
It seems that my drawing was not clear enough, here is another one which is a bit simpler in order to illustrate the problem of 2D + depth with reprojection :

The upper left part shows a scene containing a plain green cube seen from above, the red lines indicate where there is depth information. The lower left shows the rendered frame as it appears on the screen and the depth map extracted from the depth buffer.
The upper right part shows the same scene, this time with the two cameras that will be used to render the frames for each by reprojection. The red lines are at the same position than in the previous representation. The lower right shows the rendered frames calculated by reprojection.
You can clearly see that there is missing depth information when we render the frames from the left and right cameras (black zones).
A solution must thus be found to determine what is the color of the pixels in these zones. The correct way would be to re-render the left and right frames only for these zones which could be costly.
The CryEngine use bilinear filtering by interpolating the colors in the missing zones. In this case, the black zones would be rendered as a gradient from green to blue, which should look quite weird in this scene but could be acceptable with a real textured scene.
EDIT: Duh, Cybereality beat me to it, nice job !
The upper left part shows a scene containing a plain green cube seen from above, the red lines indicate where there is depth information. The lower left shows the rendered frame as it appears on the screen and the depth map extracted from the depth buffer.
The upper right part shows the same scene, this time with the two cameras that will be used to render the frames for each by reprojection. The red lines are at the same position than in the previous representation. The lower right shows the rendered frames calculated by reprojection.
You can clearly see that there is missing depth information when we render the frames from the left and right cameras (black zones).
A solution must thus be found to determine what is the color of the pixels in these zones. The correct way would be to re-render the left and right frames only for these zones which could be costly.
The CryEngine use bilinear filtering by interpolating the colors in the missing zones. In this case, the black zones would be rendered as a gradient from green to blue, which should look quite weird in this scene but could be acceptable with a real textured scene.
EDIT: Duh, Cybereality beat me to it, nice job !
Last edited by Fredz on Wed Nov 17, 2010 9:26 pm, edited 1 time in total.
-
Dom

- Diamond Eyed Freakazoid!
- Posts: 824
- Joined: Sun Oct 19, 2008 12:30 pm
- Contact:
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
Does the camera lens size affect how much information can be seen? So considering your two eyes have more visual space than with just one eye open. Then having a huge camera lens that would capture the same amount of space that you would see with two cameras would this give any better results. Then use magnification and image ratio sizing to give a more lifelike and clear perspective.
http://www.cns-nynolyt.com/files/doms-systemspecs.html My System specs In HTML

Cyberia on Youtube
__________________________________________________________________________________________

Cyberia on Youtube
__________________________________________________________________________________________
-
Fredz
- Petrif-Eyed
- Posts: 2255
- Joined: Sat Jan 09, 2010 2:06 pm
- Location: Perpignan, France
- Contact:
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
Using a different lens won't change anything, it'll only stretch the scene but depth information will still be missing.
-
cybereality
- 3D Angel Eyes (Moderator)
- Posts: 11407
- Joined: Sat Apr 12, 2008 8:18 pm
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
Ok, I have taken some screenshots of Tomb Raider using the latest TriDef driver in Virtual3D mode. This mode uses the games z-buffer to generate the "virtual" 3D. I think it pretty clearly shows that 2D+depth is an inferior technology and in no way, shape, or form can ever compete with a true stereoscopic dual render. These images are cross-eye images, so feel free to free-view them or save to your computer and rename as "*.jps" to open with your favorite 3D image viewing application. I think the images speak for themselves.
Real 3D: Fake 3D: Clearly the "fake 3D" does not look that great. For example, look at the lamppost on the left (adjacent to the box). Notice how it is oddly distorted and also the boxes left edge is not a straight line. Look at Lara's left shoulder, notice the door in the background is at a weird angle. When you look at the image in 3D you can see how shallow the depth appears. Not only that but it seems somehow wrong. Like objects are not at the correct depths. For example, the ship deck in the background almost seems at the same depth as Lara Croft is. Not right at all. Overall the image is low quality and does not compare favorably to the real 3D image.
Real 3D: Fake 3D: Clearly the "fake 3D" does not look that great. For example, look at the lamppost on the left (adjacent to the box). Notice how it is oddly distorted and also the boxes left edge is not a straight line. Look at Lara's left shoulder, notice the door in the background is at a weird angle. When you look at the image in 3D you can see how shallow the depth appears. Not only that but it seems somehow wrong. Like objects are not at the correct depths. For example, the ship deck in the background almost seems at the same depth as Lara Croft is. Not right at all. Overall the image is low quality and does not compare favorably to the real 3D image.
You do not have the required permissions to view the files attached to this post.
-
crim3
- Certif-Eyed!
- Posts: 642
- Joined: Sat Sep 22, 2007 3:11 am
- Location: Valencia (Spain)
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
Chiefwinston, could it be that you are talking about a transport format for stereoscopic information while the rest is talking about rendering methods of a stereoscopic scene?
Zalman Trimon ZM-M220W / Acer H5360 with Another Eye2000 shutters / nVIDIA GTX760
-
Chiefwinston

- Diamond Eyed Freakazoid!
- Posts: 712
- Joined: Fri Jun 19, 2009 8:05 pm
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
Crim3, yer way closer than the rest. There seems to be dislays that can handle the raw format. Tho I've never seen one.crim3 wrote:Chiefwinston, could it be that you are talking about a transport format for stereoscopic information while the rest is talking about rendering methods of a stereoscopic scene?
Cyberreality well I'm sorry, but. Hey this is very advanced mathmatics. Your attempts at converting to side by side. Well your not even remotely considering a volumetric constant. Nor are you adjusting the 2D image in a fashion that would be consistant with 2d+depth to side by side imaging conversion.
2D+depth is volumetric in nature. That why you can go from 2D+depth to all other displaying formats. Its a true 3D stereo format. There just seems to be huge mis-understanding regarding it.
cheers
AMD HD3D
i7
DDD
PS3
Panasonic Plasma VT25 50" (Full HD 3D)
Polk Audio- Surround 7.1
Serving up my own 3D since 1996.
(34) Patents
i7
DDD
PS3
Panasonic Plasma VT25 50" (Full HD 3D)
Polk Audio- Surround 7.1
Serving up my own 3D since 1996.
(34) Patents
-
BlackShark

- Certif-Eyable!
- Posts: 1156
- Joined: Sat Dec 22, 2007 3:38 am
- Location: Montpellier, France
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
It seems you are idealizing 2D + depth, it's definitely not a volumetric format.
Well actually you could see it as a volumetric format restricted in the way that it can only define only one layer of voxel data, just like you could say a 2D picture is 3D information contained in a single plane.
2D + depth is a 3D format but is not a stereo image format because it cannot reproduce all the data a stereo image requires.
Well actually you could see it as a volumetric format restricted in the way that it can only define only one layer of voxel data, just like you could say a 2D picture is 3D information contained in a single plane.
2D + depth is a 3D format but is not a stereo image format because it cannot reproduce all the data a stereo image requires.
Passive 3D forever !
DIY polarised dual-projector setup :
2x Epson EH-TW3500 (2D 1080p)
Xtrem Screen Daylight 2.0, for polarized 3D
3D Vision gaming with signal converter : VNS Geobox 501
DIY polarised dual-projector setup :
2x Epson EH-TW3500 (2D 1080p)
Xtrem Screen Daylight 2.0, for polarized 3D
3D Vision gaming with signal converter : VNS Geobox 501
-
Chiefwinston
- Diamond Eyed Freakazoid!
- Posts: 712
- Joined: Fri Jun 19, 2009 8:05 pm
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
Sorry guys don't take it personal. But not seeing it as volumetric seems to be were most of you mis-apply its usefulnessBlackShark wrote:It seems you are idealizing 2D + depth, it's definitely not a volumetric format.
Well actually you could see it as a volumetric format restricted in the way that it can only define only one layer of voxel data, just like you could say a 2D picture is 3D information contained in a single plane.
2D + depth is a 3D format but is not a stereo image format because it cannot reproduce all the data of a stereo image.
-
Likay

- Petrif-Eyed
- Posts: 2913
- Joined: Sat Apr 07, 2007 4:34 pm
- Location: Sweden
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
The only good use for 2d+depth is that the rendering process isn't particularly resourcedemanding. 2d+depth may actually be the salvation for multiview displays like zecotek or similar (zecotek uses 2d+depth natively and has inbuilt chip to render all 80 views....). 2d+depth does not replace true stereoscopy and even if transfered as 2d+depth (texture+depthmap) it can never look as natural as a true stereoscopic image. It's simply the nature of its limitations. The depthmap varies (sometimes one eye view is the rendered while the other eye gets the same image "bumpmapped") between the left and right eyeviews but the 2d-texture is the same. 2d+depth is a limited format but within a gameengine developers are able to use some tricks to make the image look better/true. But then it's not really just 2d+depth anymore...
As for the transmission protocol when using 2d+depth the limits are basically the same. There are two different images but instead of left+right eye views one 2d-texturemap and one grayscale-depthmap is transfered. The 2d+depth protocol suffers from the same limitations here as well.
As for the transmission protocol when using 2d+depth the limits are basically the same. There are two different images but instead of left+right eye views one 2d-texturemap and one grayscale-depthmap is transfered. The 2d+depth protocol suffers from the same limitations here as well.
Last edited by Likay on Thu Nov 18, 2010 1:15 pm, edited 1 time in total.
Mb: Asus P5W DH Deluxe
Cpu: C2D E6600
Gb: Nvidia 7900GT + 8800GTX
3D:100" passive projector polarized setup + 22" IZ3D

Cpu: C2D E6600
Gb: Nvidia 7900GT + 8800GTX
3D:100" passive projector polarized setup + 22" IZ3D
-
yuriythebest

- Petrif-Eyed
- Posts: 2476
- Joined: Mon Feb 04, 2008 12:35 pm
- Location: Kiev, ukraine
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
I'm having difficulty understanding what everyone here is trying to prove. Can the data from Kinect be used to create some kind of stereoscopic image? Sure. Would you want to - no, better get something like the minoru3d that is way cheaper and does this out of the box.
If you are asking if 2d+depthmap is a recognized 3d format then yes, all be it an obscure one. Philips uses it, and once autostereoscopic displays become popular I imagine we'll see a lot more of it

EDIT: WTFFF!!!?? I crossed my eyes on the above image and was able to see depth. The background is clearly behind the character and the steel beam and the character is in front (all be it flat). one of his legs is a bit further behind. wow. sure there is a lot of retinal rivlary but it works.. somehow...
Anyhow I've quickly and dirtily made it into a stereoscopic image using 3ds max

and here is how it was done - the displacement/depth map was used to, um, "displace" the image

If you are asking if 2d+depthmap is a recognized 3d format then yes, all be it an obscure one. Philips uses it, and once autostereoscopic displays become popular I imagine we'll see a lot more of it
EDIT: WTFFF!!!?? I crossed my eyes on the above image and was able to see depth. The background is clearly behind the character and the steel beam and the character is in front (all be it flat). one of his legs is a bit further behind. wow. sure there is a lot of retinal rivlary but it works.. somehow...
Anyhow I've quickly and dirtily made it into a stereoscopic image using 3ds max
and here is how it was done - the displacement/depth map was used to, um, "displace" the image
Oculus Rift / 3d Sucks - 2D FTW!!!
-
Likay
- Petrif-Eyed
- Posts: 2913
- Joined: Sat Apr 07, 2007 4:34 pm
- Location: Sweden
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
Great illustrated Yuriy and 2d+depth can't be pictured better than this!
Tried crosseyeing the 2d+grayscale depthmap but the retinal rivalry takes over anything so no luck.
Tried crosseyeing the 2d+grayscale depthmap but the retinal rivalry takes over anything so no luck.
Mb: Asus P5W DH Deluxe
Cpu: C2D E6600
Gb: Nvidia 7900GT + 8800GTX
3D:100" passive projector polarized setup + 22" IZ3D
Cpu: C2D E6600
Gb: Nvidia 7900GT + 8800GTX
3D:100" passive projector polarized setup + 22" IZ3D
-
IN65498

- One Eyed Hopeful
- Posts: 20
- Joined: Sat May 12, 2007 1:09 pm
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
What this demo shows is a flaw for any system lacking a whole array of cameras, this means you don't have informations about hidden areas, so technically it's not restricted to 2D, although evidently with 2 cameras you have a HUGE improvement over 1.
If the flaw of 2D+depth were this, it would mean that we'd be missing the required information to see the rendered image when rotated.
But you never rotate the rendered image! When you want to rotate objects in a game, the engine provides you with another image, containing all that's needed to see from the new perspective.
I imagine the flaw of 2D+depth, in pc games, to be more about approximations at the borders of objects, maybe smudged textures, especially unconvincing light-shadow etc. effects.
If the flaw of 2D+depth were this, it would mean that we'd be missing the required information to see the rendered image when rotated.
But you never rotate the rendered image! When you want to rotate objects in a game, the engine provides you with another image, containing all that's needed to see from the new perspective.
I imagine the flaw of 2D+depth, in pc games, to be more about approximations at the borders of objects, maybe smudged textures, especially unconvincing light-shadow etc. effects.
-
Likay
- Petrif-Eyed
- Posts: 2913
- Joined: Sat Apr 07, 2007 4:34 pm
- Location: Sweden
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
I've just started to get some experience myself using tridefs virtual 3d but here's my pov so far: Imo the only advantage seems to be better performance while the visual appearence is hard to enjoy compared to true stereoscopy. When i get close to objects smaller anomalies starts being really disturbing. Playing using very little depth or with objects far into the screen isn't especially appealing either. I could visually get the exactly same effect (on far away objects stereoscopy is minimized because both eyes gets almost the same image...) by using clonemode and just shifting one projector sideways...
On the other hand: Most games as is today seems to be bound with some kind of anomalies in true-3d which you have to live with and in this regard the virtual mode isn't too bad in comparison. I have yet to find a game where i prefer the virtual mode before real 3d though.
I'm not getting hopeful about 2d+depth as image but i'll reserve my "definite so far... " opinion until crytek shows what they've got.
On the other hand: Most games as is today seems to be bound with some kind of anomalies in true-3d which you have to live with and in this regard the virtual mode isn't too bad in comparison. I have yet to find a game where i prefer the virtual mode before real 3d though.
I'm not getting hopeful about 2d+depth as image but i'll reserve my "definite so far...
Mb: Asus P5W DH Deluxe
Cpu: C2D E6600
Gb: Nvidia 7900GT + 8800GTX
3D:100" passive projector polarized setup + 22" IZ3D
Cpu: C2D E6600
Gb: Nvidia 7900GT + 8800GTX
3D:100" passive projector polarized setup + 22" IZ3D
-
Chiefwinston
- Diamond Eyed Freakazoid!
- Posts: 712
- Joined: Fri Jun 19, 2009 8:05 pm
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
Okay lets try this. Maybe it will help.
1.) We take an autostereoscopic display. lets say its also, the greatest autostereoscopic display ever made.
2.) It's now displaying a static 3d image. It looks fantastic. Its also, in its native 2D + depth format. Everyone is standing around going wow I want one.
3.) A guy walks up. Takes his tripod out. Sets up his high end fuji 3D camera. Snaps a side by side 3D photo.
4.) So what of the following is going to happen.
a)Will the photo show a perfect 3D image.
b)There will be missing info in the new side by side 3D photo and it just won't look right.
c)hmmm, I just don't know.
This is what I believe the 2d+depth game makers are racing to do mathmatically.
cheers
1.) We take an autostereoscopic display. lets say its also, the greatest autostereoscopic display ever made.
2.) It's now displaying a static 3d image. It looks fantastic. Its also, in its native 2D + depth format. Everyone is standing around going wow I want one.
3.) A guy walks up. Takes his tripod out. Sets up his high end fuji 3D camera. Snaps a side by side 3D photo.
4.) So what of the following is going to happen.
a)Will the photo show a perfect 3D image.
b)There will be missing info in the new side by side 3D photo and it just won't look right.
c)hmmm, I just don't know.
This is what I believe the 2d+depth game makers are racing to do mathmatically.
cheers
AMD HD3D
i7
DDD
PS3
Panasonic Plasma VT25 50" (Full HD 3D)
Polk Audio- Surround 7.1
Serving up my own 3D since 1996.
(34) Patents
i7
DDD
PS3
Panasonic Plasma VT25 50" (Full HD 3D)
Polk Audio- Surround 7.1
Serving up my own 3D since 1996.
(34) Patents
-
Likay
- Petrif-Eyed
- Posts: 2913
- Joined: Sat Apr 07, 2007 4:34 pm
- Location: Sweden
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
B is the closest and this is what happens:
The photo taken will show the image of the television as it is, with the flaws the 2d+depthformat have and as everybody see it. True stereoscopy (stereocamera with left+right image for instance) is true to the scene and it will capture it as it is while 2d+depth format can't be used as a format for true-3d capturing because important depthinformation will be lost. Lost in games as in real world. There are occasions where i have a hard time telling the difference between a 2d+depth and a true stereoscopic image but most times 2d+depth won't cut it regarding quality of image and impression.
There's no perspective information in 2d+depth. Just one 2d-image + a depthmap exactly like Yuriy shows. As many explains it's impossible to show a true volumetric image using 2d+depth. The actual sourcetexture is 2d and this is the main flaw.
It's not so easy to make a 2d+depthmap from a true stereoscopic image while it's a lot easier to make a virtually stereoscopic image of a 2d+depth image like Yuriy just made.
The photo taken will show the image of the television as it is, with the flaws the 2d+depthformat have and as everybody see it. True stereoscopy (stereocamera with left+right image for instance) is true to the scene and it will capture it as it is while 2d+depth format can't be used as a format for true-3d capturing because important depthinformation will be lost. Lost in games as in real world. There are occasions where i have a hard time telling the difference between a 2d+depth and a true stereoscopic image but most times 2d+depth won't cut it regarding quality of image and impression.
There's no perspective information in 2d+depth. Just one 2d-image + a depthmap exactly like Yuriy shows. As many explains it's impossible to show a true volumetric image using 2d+depth. The actual sourcetexture is 2d and this is the main flaw.
It's not so easy to make a 2d+depthmap from a true stereoscopic image while it's a lot easier to make a virtually stereoscopic image of a 2d+depth image like Yuriy just made.
Mb: Asus P5W DH Deluxe
Cpu: C2D E6600
Gb: Nvidia 7900GT + 8800GTX
3D:100" passive projector polarized setup + 22" IZ3D
Cpu: C2D E6600
Gb: Nvidia 7900GT + 8800GTX
3D:100" passive projector polarized setup + 22" IZ3D
-
BlackShark
- Certif-Eyable!
- Posts: 1156
- Joined: Sat Dec 22, 2007 3:38 am
- Location: Montpellier, France
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
There is no such 2D+depth native autostereoscopic display.
Philips Wowvx uses 2D+depth as a transmission format only, the panel is a 9 eye multi-view through a lenticular array : a chip inside the TV extrapolates the 9 eye multi-views from the 2D+depth format.
Stereo pairs of pictures contain more 2D information in the areas that are occluded in one eye but visible in the other.
Philips Wowvx uses 2D+depth as a transmission format only, the panel is a 9 eye multi-view through a lenticular array : a chip inside the TV extrapolates the 9 eye multi-views from the 2D+depth format.
Actually no, 2D+depth contains more depth information than a stereo pair of pictures since it contains depth information for every single pixel.Likay wrote:2d+depth format can't be used as a format for true-3d capturing because important depthinformation will be lost..
Stereo pairs of pictures contain more 2D information in the areas that are occluded in one eye but visible in the other.
Passive 3D forever !
DIY polarised dual-projector setup :
2x Epson EH-TW3500 (2D 1080p)
Xtrem Screen Daylight 2.0, for polarized 3D
3D Vision gaming with signal converter : VNS Geobox 501
DIY polarised dual-projector setup :
2x Epson EH-TW3500 (2D 1080p)
Xtrem Screen Daylight 2.0, for polarized 3D
3D Vision gaming with signal converter : VNS Geobox 501
-
Neil

- 3D Angel Eyes (Moderator)
- Posts: 6882
- Joined: Wed Dec 31, 1969 6:00 pm
- Contact:
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
So....how would 2D+depth handle this:
[youtube-hd]http://www.youtube.com/watch?v=kXraSkgssFk[/youtube-hd]
Kidding!!!
Regards,
Neil
[youtube-hd]http://www.youtube.com/watch?v=kXraSkgssFk[/youtube-hd]
Kidding!!!
Regards,
Neil
-
Fredz
- Petrif-Eyed
- Posts: 2255
- Joined: Sat Jan 09, 2010 2:06 pm
- Location: Perpignan, France
- Contact:
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
True stereoscopy doesn't completely capture the geometry of a scene, it does only capture it for 2 viewpoints. When eye tracking displays like the AUO laptop will become more popular, we'll also see the limits of this technique when viewing 3D movies.Likay wrote:True stereoscopy (stereocamera with left+right image for instance) is true to the scene and it will capture it as it is
Sure, part of the depth information is lost but for games I've still hope that someone will find a technique to correct the missing parts. It's not like in 3D movies where you only have access to the two images, you've also got access to the whole geometry of the scene.Likay wrote:while 2d+depth format can't be used as a format for true-3d capturing because important depthinformation will be lost. Lost in games as in real world.
It's not really fair to say that 2D + depth can't produce volumetric images, it can still do it for most parts of a scene, just not for the edges.Likay wrote:There's no perspective information in 2d+depth. Just one 2d-image + a depthmap exactly like Yuriy shows. As many explains it's impossible to show a true volumetric image using 2d+depth. The actual sourcetexture is 2d and this is the main flaw.
There's a lot of ongoing research on this subject and while the results are still not perfect, they've been quite encouraging for now. See the Middlebury Stereo Evaluation for recent advances in this field :Likay wrote:It's not so easy to make a 2d+depthmap from a true stereoscopic image
http://vision.middlebury.edu/stereo/eval/" onclick="window.open(this.href);return false;
I'm especially excited by the technique curently ranked at the first place in this evaluation, the corresponding paper will be published at the next CVPR conference in 2011.
Here is an example of automatic depthmap reconstruction from three images, using the technique ranked at the second place in the evaluation :


And here is an example of depth maps recovery from a video sequence filmed with only one camera :


The project homepage has also some video results that look quite impressive :
http://www.cad.zju.edu.cn/home/gfzhang/ ... ideodepth/" onclick="window.open(this.href);return false;
It's easy to do it quickly by displacing the 2D image using the depth information like Yuri did, but it'll be a lot more complicated to find a technique that gives acceptable results for edges.Likay wrote:while it's a lot easier to make a virtually stereoscopic image of a 2d+depth image like Yuriy just made.
Maybe it would be possible to use techniques of object removal from images, they could be useful to estimate the colors of the pixels in the background for regions with depth discontinuities. See this page for an example of object removal in static images :
http://research.microsoft.com/en-us/pro ... works.aspx" onclick="window.open(this.href);return false;
-
mar10br0

- One Eyed Hopeful
- Posts: 10
- Joined: Mon Nov 30, 2009 3:25 am
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
Okay, some here are really talking about different things...
Both stereo-3D and 2D+depth contain information for one and only (1) viewpoint, extrapolating to other viewpoints purely from a given stereo-3D or 2D+depth will result in less accuracy in either (they miss information, but different kind of information). Used for their purpose of transporting a static scene (single frame in movie/game) they both have pros and cons:
stereo-3D:
pro = contains the exact info needed to present an image for both human eyes in the position of the camera-viewpoint, so gives a 'true' 3-dimensional scene to the brain
con = 2 full images with a lot of similar info (high bandwidth requirement)
2D+depth:
pro = per line of view only one color and a depth-value is given, depth can be given with less bandwidth than true color, so lower bandwidth requirement
con = some visible information is missing for at least one eye where a foreground-object is obscuring a background-object (one eye would look past the foreground object's edge seeing something the other eye doesn't, the 2D image-part of the format cannot give that piece of info. In more technical terms: the format has problems with parallax.
The computational argument is also dubious: the stereo-3D format requires 2 full color images to be rendered (but many optimisations exist to reduce the total amount to less than double a single 2D image). But a stereo-3D image can be presented to your 2 eyes without any kind of computations. A 2D+depth image requires less computations from scene-data, but is not "native" to a human and requires further computations to generate images for 2 eyes, the depth-information is used to position a given 2D pixel differently in the images shown to the eyes. This can result in missing pixels in either image which then need to be interpolated/guessed (higher quality comes at a cost of more complex computations).
To know the full benefits/drawback of using a particular format in a particular part of the path from original scene (real world or internal game-data) all the way to the audience many factors play a role and 2D+depth may give advantages over stereo-3D in certain parts where the concessions to quality are acceptable.
I believe that stereo-3D is quality-wise superior over 2D+depth just because it is "native" to the human with 2 eyes and no data-intra/extrapolations are required. I also believe that smart compression techniques may reduce the difference in bandwidth-requirements between these 2 formats (left/right images are much more similar than a 2D-image and its depth-map). I expect dedicated stereo-3D image/video-compression algorithms will appear in the near future.
And finally a remark on the original topic of the article:
I don't see the Kinect as a true 2D+depth solution: it uses 2 cameras at different viewpoints and is therefore a stereo-3D recorder (albeit a crippled one with only one recording color). It then uses this almost-stereo-3D to compute 2D+depth data. A true 2D+depth recorder would be a single camera with a radar (measuring the distance between camera and object for each pixel).
Both stereo-3D and 2D+depth contain information for one and only (1) viewpoint, extrapolating to other viewpoints purely from a given stereo-3D or 2D+depth will result in less accuracy in either (they miss information, but different kind of information). Used for their purpose of transporting a static scene (single frame in movie/game) they both have pros and cons:
stereo-3D:
pro = contains the exact info needed to present an image for both human eyes in the position of the camera-viewpoint, so gives a 'true' 3-dimensional scene to the brain
con = 2 full images with a lot of similar info (high bandwidth requirement)
2D+depth:
pro = per line of view only one color and a depth-value is given, depth can be given with less bandwidth than true color, so lower bandwidth requirement
con = some visible information is missing for at least one eye where a foreground-object is obscuring a background-object (one eye would look past the foreground object's edge seeing something the other eye doesn't, the 2D image-part of the format cannot give that piece of info. In more technical terms: the format has problems with parallax.
The computational argument is also dubious: the stereo-3D format requires 2 full color images to be rendered (but many optimisations exist to reduce the total amount to less than double a single 2D image). But a stereo-3D image can be presented to your 2 eyes without any kind of computations. A 2D+depth image requires less computations from scene-data, but is not "native" to a human and requires further computations to generate images for 2 eyes, the depth-information is used to position a given 2D pixel differently in the images shown to the eyes. This can result in missing pixels in either image which then need to be interpolated/guessed (higher quality comes at a cost of more complex computations).
To know the full benefits/drawback of using a particular format in a particular part of the path from original scene (real world or internal game-data) all the way to the audience many factors play a role and 2D+depth may give advantages over stereo-3D in certain parts where the concessions to quality are acceptable.
I believe that stereo-3D is quality-wise superior over 2D+depth just because it is "native" to the human with 2 eyes and no data-intra/extrapolations are required. I also believe that smart compression techniques may reduce the difference in bandwidth-requirements between these 2 formats (left/right images are much more similar than a 2D-image and its depth-map). I expect dedicated stereo-3D image/video-compression algorithms will appear in the near future.
And finally a remark on the original topic of the article:
I don't see the Kinect as a true 2D+depth solution: it uses 2 cameras at different viewpoints and is therefore a stereo-3D recorder (albeit a crippled one with only one recording color). It then uses this almost-stereo-3D to compute 2D+depth data. A true 2D+depth recorder would be a single camera with a radar (measuring the distance between camera and object for each pixel).
Last edited by mar10br0 on Thu Nov 18, 2010 10:26 pm, edited 1 time in total.
-
cybereality
- 3D Angel Eyes (Moderator)
- Posts: 11407
- Joined: Sat Apr 12, 2008 8:18 pm
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
Dude, I'm sorry, but you don't know what you're talking about. Like I explained before, I actually wrote a program to convert a 2D image and depth map to a stereo image (side by side). I know it was rudimentary algorithm, I was not trying to pass it off as it was in any way physically accurate. However, as a quick test, it shows the issues involved when converting a 2D image to a 3D image. Also, in my research I worked with a number of other 3D image conversion programs and even read some academic whitepapers. On top of that, I have actually clocked many hours playing games with the DDD TriDef driver in "Virtual 3D" mode. So I think I know what I am talking about. Please don't insult me. I think I and everyone else here has thoroughly explained this concept with diagrams and pictures to make it easy understand. When you are ready to actually learn something, go back and re-read this thread from the beginning.Chiefwinston wrote: Cyberreality well I'm sorry, but. Hey this is very advanced mathmatics. Your attempts at converting to side by side. Well your not even remotely considering a volumetric constant. Nor are you adjusting the 2D image in a fashion that would be consistant with 2d+depth to side by side imaging conversion.
-
Fredz
- Petrif-Eyed
- Posts: 2255
- Joined: Sat Jan 09, 2010 2:06 pm
- Location: Perpignan, France
- Contact:
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
It's not completely exact, in fact a stereo 3D image will give an accurate 3D representation of a scene only for people with the same IPD (interpupillary distance) than the interaxial separation of the cameras. And this can vary quite much, with a mean IPD of 63mm for adults but a range of 50-75mm for most of them, and to only 40mm for 5 years old children.mar10br0 wrote:stereo-3D: pro = contains the exact info needed to present an image for both human eyes in the position of the camera-viewpoint, so gives a 'true' 3-dimensional scene to the brain
And as you said, it will also only be accurate if the viewer is exactly at the same position than the cameras, ie. dead center to the screen and at the same distance from the scene. If it's not the case, the distorsion could be quite bad :

The MVC video compression standard used in Blu-Ray 3D does this already, with a 50% overhead compared to equivalent 2D content.mar10br0 wrote:I also believe that smart compression techniques may reduce the difference in bandwidth-requirements between these 2 formats (left/right images are much more similar than 2D-image and depth-map). I expect to see dedicated stereo-3D image/video-compression algorithms will appear in the near future.
I fail to see the difference between a true 2D + depth recorder and what you call a stereo 3D recorder. The Kinect works just like a time-of-flight camera to me, the result should be the same even if the technique used is a little bit different.mar10br0 wrote:I also don't see the Kinect as a true 2D+depth solution: it uses 2 cameras at different viewpoints and is therefore a stereo-3D recorder (albeit a crippled one with only one recording color). A true 2D+depth recorder would be a single camera with a radar (measuring the distance between camera and object for each pixel).
-
mar10br0
- One Eyed Hopeful
- Posts: 10
- Joined: Mon Nov 30, 2009 3:25 am
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
Hi Fredz,
Yep, agree with you on the IPD issue. And the 2D+depth would not have that issue. About the angle to the scene, both formats assume the audience to be in front of the screen at a given distance.
What I meant with the Kinect not truly 2D+depth, is that the 2D+depth format is used after the sensors. The sensors are stereo (or I understand even triple) with parallax. It all depends on what you consider the "recorder". In the path from scene to brains, the Kinect senses in stereo-3D, then transports in 2D+depth to the console. And you're right, from the console point of view it doesn't matter how much or little is done before that, it still receives 2D+depth data...
Marco
Yep, agree with you on the IPD issue. And the 2D+depth would not have that issue. About the angle to the scene, both formats assume the audience to be in front of the screen at a given distance.
What I meant with the Kinect not truly 2D+depth, is that the 2D+depth format is used after the sensors. The sensors are stereo (or I understand even triple) with parallax. It all depends on what you consider the "recorder". In the path from scene to brains, the Kinect senses in stereo-3D, then transports in 2D+depth to the console. And you're right, from the console point of view it doesn't matter how much or little is done before that, it still receives 2D+depth data...
Marco


-
Chiefwinston
- Diamond Eyed Freakazoid!
- Posts: 712
- Joined: Fri Jun 19, 2009 8:05 pm
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
I see some of you are concerned with occluded area's. See if this helps.
1)We take a scene of (3) objects: a man, a cup, and a table. Instead of taking one 2D+depth map of the scene. We make take an individual 2d+depth map snap shot of the man without the cup and table, then we take an individual 2d+depth map snap shot of the table without the man and cup,- then take an individual 2d+depth map snap shot of the cup without the man and table. These are all isolated snapshots with out a background and at the same moment in time and from one stationary camera position.
2)we now generate computationally 3 side by side images from these original 2d+depth files-for usable stereoscopic viewing.
3)We create a composite with the new side by side images. Layer 1 is the man, layer 2 is the table, and layer 3 is the cup.
Do you see were I'm going? 2D+depth is a mathmatical tool. When used with compositing you end up without occluded information.
Or how about this:
We take a single frame from a game. This frame is a side by side 3D image created from traditional 2 camera views. It shows two men arguing. We generate a new background from a 2D+depth file. This 2D +depth file will need alot of volumetric info from the first file in order to be done correctly. But agian we can create a new side by side 3d image. This new 3D image is now layer 2. So computationally we can create a hybrid of a (2) camera generated side by side image and composite with a side by side image created using the 2D+depth technique.
cool eh?
I've noticed a few remarks regarding issues around the "edges". Yes this is missing info. Through scaling this can be reduced to less than one pixel. So theoretically you wouldn't see it. Because it falls below the displayed resolution.
I wouldn't be too discouraged with the bad 3d thats currently floating around using this technique. It has a very solid footing in volumetric mathmatics. It may take a while for proper implementation.
Fake 3D- nope. Poorly implemented- Yup.
cheers
1)We take a scene of (3) objects: a man, a cup, and a table. Instead of taking one 2D+depth map of the scene. We make take an individual 2d+depth map snap shot of the man without the cup and table, then we take an individual 2d+depth map snap shot of the table without the man and cup,- then take an individual 2d+depth map snap shot of the cup without the man and table. These are all isolated snapshots with out a background and at the same moment in time and from one stationary camera position.
2)we now generate computationally 3 side by side images from these original 2d+depth files-for usable stereoscopic viewing.
3)We create a composite with the new side by side images. Layer 1 is the man, layer 2 is the table, and layer 3 is the cup.
Do you see were I'm going? 2D+depth is a mathmatical tool. When used with compositing you end up without occluded information.
Or how about this:
We take a single frame from a game. This frame is a side by side 3D image created from traditional 2 camera views. It shows two men arguing. We generate a new background from a 2D+depth file. This 2D +depth file will need alot of volumetric info from the first file in order to be done correctly. But agian we can create a new side by side 3d image. This new 3D image is now layer 2. So computationally we can create a hybrid of a (2) camera generated side by side image and composite with a side by side image created using the 2D+depth technique.
cool eh?
I've noticed a few remarks regarding issues around the "edges". Yes this is missing info. Through scaling this can be reduced to less than one pixel. So theoretically you wouldn't see it. Because it falls below the displayed resolution.
I wouldn't be too discouraged with the bad 3d thats currently floating around using this technique. It has a very solid footing in volumetric mathmatics. It may take a while for proper implementation.
Fake 3D- nope. Poorly implemented- Yup.
cheers
Last edited by Chiefwinston on Sat Nov 20, 2010 10:30 am, edited 1 time in total.
AMD HD3D
i7
DDD
PS3
Panasonic Plasma VT25 50" (Full HD 3D)
Polk Audio- Surround 7.1
Serving up my own 3D since 1996.
(34) Patents
i7
DDD
PS3
Panasonic Plasma VT25 50" (Full HD 3D)
Polk Audio- Surround 7.1
Serving up my own 3D since 1996.
(34) Patents
-
Chiefwinston
- Diamond Eyed Freakazoid!
- Posts: 712
- Joined: Fri Jun 19, 2009 8:05 pm
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
umm yeah, compositing will also help with glass, smoke, transparencies...ect.
cheers
cheers
-
cybereality
- 3D Angel Eyes (Moderator)
- Posts: 11407
- Joined: Sat Apr 12, 2008 8:18 pm
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
Again, Chiefwinston, I think you are missing the point. The whole draw of using 2D+depth (at least for gaming), is that you are saving on performance. The only additional overhead is the conversion of the depthmap to the stereo image pairs, and this has been shown to be negligible (ie for the DDD driver or alleged performance in Crysis 2). However what you are suggesting is to take 3 separate color images and 3 depthmaps. This doesn't make any sense. If you have 3 renders from different angles then you already have the stereo 3d pairs. Why would you then take each image in 2D, extrapolate depth using a depthmap, and then convert that to the stereo image pairs you had in the beginning. This would be even more computationally expensive than just rendering the 2 views by the standard brute force method. Not only that, but your example wouldn't really work realistically. I mean, are you saying you would have to render a different frame for every object in the scene. How about a crowded train station with hundreds of people? Or a vast forest with 100's of trees and 1000's of blades of grass? Are you to render a separate color image and depth map for every tree and blade of grass? Your example just falls apart with any real world scenario.
I think you are misunderstanding the technique used in 2D+depth. It is not using full volumetric data (like with voxels, for example). So you cannot represent any overlapping objects at all. This is not a trivial issue, it is a fundamental limitation of the format. Filling in this missing data caused by occluded areas can be done, but it is not very accurate. As was shown with the Tomb Raider pictures I posted, this causes strange distortion on the surrounding pixels and just doesn't look very good at all. At low separation, it can be acceptable, but it is no substitution for a real 3D image. I am not saying that technology won't improve, but there are fundamental limitations that cannot be overcome. One of them is the occluded areas, which is a huge issue. In certain cases, entire objects (like a whole person) would be visible in one eye, but not the other. If the 2D image we had was from the eye without the person, no algorithm could EVER be created in a billion years that would bring this person back into the image. Its literally impossible, end of story. Not to mention other issues, such as transparent or translucent objects. How could you capture the depth of looking at objects out a window if the depth map only senses the depth of the window itself? Not an easy problem to overcome. Also, reflective objects are also a problem: glossy cars, mirrors, etc. Since you see a different reflection in each eye (essentially a 3D reflection), a 2D+depth format could not accurately recreate this experience. All these issues put together result in a sub-par "3D" image which is never going to match a true stereoscopic source. Now, that is not to say that I think 3D always has to mean using 2 cameras. In fact, a true volumetric representation (ie voxels at ultra-HD resolutions) could actually be way more accurate and visually impressive than current 2 image stereo 3D. And if auto-stereo displays become popular in the future, then we will have to think about how we are generating 64, 128 or more views of a scene. In this case, using volumetric data makes more sense, since rendering a game 128 times is probably not feasible. However, even in this case, 2D+depth is still not adequate. We can just barely produce acceptable quality interpolated images for 2 views, imagine all the missing data you have to deal with in getting 128 views out of a single 2D image! The format is just very limiting. But it could be the basis for better things in the future, I don't know. But where its at now is not that impressive.
I think you are misunderstanding the technique used in 2D+depth. It is not using full volumetric data (like with voxels, for example). So you cannot represent any overlapping objects at all. This is not a trivial issue, it is a fundamental limitation of the format. Filling in this missing data caused by occluded areas can be done, but it is not very accurate. As was shown with the Tomb Raider pictures I posted, this causes strange distortion on the surrounding pixels and just doesn't look very good at all. At low separation, it can be acceptable, but it is no substitution for a real 3D image. I am not saying that technology won't improve, but there are fundamental limitations that cannot be overcome. One of them is the occluded areas, which is a huge issue. In certain cases, entire objects (like a whole person) would be visible in one eye, but not the other. If the 2D image we had was from the eye without the person, no algorithm could EVER be created in a billion years that would bring this person back into the image. Its literally impossible, end of story. Not to mention other issues, such as transparent or translucent objects. How could you capture the depth of looking at objects out a window if the depth map only senses the depth of the window itself? Not an easy problem to overcome. Also, reflective objects are also a problem: glossy cars, mirrors, etc. Since you see a different reflection in each eye (essentially a 3D reflection), a 2D+depth format could not accurately recreate this experience. All these issues put together result in a sub-par "3D" image which is never going to match a true stereoscopic source. Now, that is not to say that I think 3D always has to mean using 2 cameras. In fact, a true volumetric representation (ie voxels at ultra-HD resolutions) could actually be way more accurate and visually impressive than current 2 image stereo 3D. And if auto-stereo displays become popular in the future, then we will have to think about how we are generating 64, 128 or more views of a scene. In this case, using volumetric data makes more sense, since rendering a game 128 times is probably not feasible. However, even in this case, 2D+depth is still not adequate. We can just barely produce acceptable quality interpolated images for 2 views, imagine all the missing data you have to deal with in getting 128 views out of a single 2D image! The format is just very limiting. But it could be the basis for better things in the future, I don't know. But where its at now is not that impressive.
-
Chiefwinston
- Diamond Eyed Freakazoid!
- Posts: 712
- Joined: Fri Jun 19, 2009 8:05 pm
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
cybereality first off don't take it personally. Your a cool dude. Second, I've edited my above post. I've tried to make it a little more clear. I'm mearly trying to show threw example how you can end up with a viewable stereoscopic scene without occlusions. Your examples continually show the limitations of 2D+depth when used in fake 3D.
A more acurate description may be 2D+depth of a single object without a background. Its a computational tool, much like pi, e, e=mc2. Its simply brilliant. For a complex true 3D streoscopic scene multiple rendering passes would be needed to build-up a great looking scene- much like what is already happening in a game engine. I'm talking of a game engine here. 2D+depth has limited if any uses outside of being used for computionally generating a stereo pair.
hmm don't worry guys. Grasping it. Well its deep sh!t. And none of you are stupid. Great thread tho.
cheers
A more acurate description may be 2D+depth of a single object without a background. Its a computational tool, much like pi, e, e=mc2. Its simply brilliant. For a complex true 3D streoscopic scene multiple rendering passes would be needed to build-up a great looking scene- much like what is already happening in a game engine. I'm talking of a game engine here. 2D+depth has limited if any uses outside of being used for computionally generating a stereo pair.
hmm don't worry guys. Grasping it. Well its deep sh!t. And none of you are stupid. Great thread tho.
cheers
AMD HD3D
i7
DDD
PS3
Panasonic Plasma VT25 50" (Full HD 3D)
Polk Audio- Surround 7.1
Serving up my own 3D since 1996.
(34) Patents
i7
DDD
PS3
Panasonic Plasma VT25 50" (Full HD 3D)
Polk Audio- Surround 7.1
Serving up my own 3D since 1996.
(34) Patents
-
Chiefwinston
- Diamond Eyed Freakazoid!
- Posts: 712
- Joined: Fri Jun 19, 2009 8:05 pm
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
And yeah most current examples show poor results. This technique will be going through many years of improvements. But the mathmatics are rock solid. It's not going to go away.
I'm gonna go play some COD:BO. Have fun.
cheers
I'm gonna go play some COD:BO. Have fun.
cheers
AMD HD3D
i7
DDD
PS3
Panasonic Plasma VT25 50" (Full HD 3D)
Polk Audio- Surround 7.1
Serving up my own 3D since 1996.
(34) Patents
i7
DDD
PS3
Panasonic Plasma VT25 50" (Full HD 3D)
Polk Audio- Surround 7.1
Serving up my own 3D since 1996.
(34) Patents
-
BlackShark
- Certif-Eyable!
- Posts: 1156
- Joined: Sat Dec 22, 2007 3:38 am
- Location: Montpellier, France
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
There is an easy example of a single object with no background where simple 2D+depth is not enough to generate a stereo pair : a sphereChiefwinston wrote: A more acurate description may be 2D+depth of a single object without a background. Its a computational tool, much like pi, e, e=mc2. Its simply brilliant.
It's been known for more than 2000years that 2 eyes see a greater surface of a sphere than one eye, no matter what the distance of size of the sphere. The difference may be more or less noticeable, but it's always mathematically there. One of the Greek mathematicians found that, I don't remember which one.
Passive 3D forever !
DIY polarised dual-projector setup :
2x Epson EH-TW3500 (2D 1080p)
Xtrem Screen Daylight 2.0, for polarized 3D
3D Vision gaming with signal converter : VNS Geobox 501
DIY polarised dual-projector setup :
2x Epson EH-TW3500 (2D 1080p)
Xtrem Screen Daylight 2.0, for polarized 3D
3D Vision gaming with signal converter : VNS Geobox 501
-
Chiefwinston
- Diamond Eyed Freakazoid!
- Posts: 712
- Joined: Fri Jun 19, 2009 8:05 pm
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
BlackShark you are correct, depending on resolution and scaling that the displacement mapping is done at. This could be reduced to less than 1 pixel. Making it more or less irrelevant for gaming.
cheers
cheers
AMD HD3D
i7
DDD
PS3
Panasonic Plasma VT25 50" (Full HD 3D)
Polk Audio- Surround 7.1
Serving up my own 3D since 1996.
(34) Patents
i7
DDD
PS3
Panasonic Plasma VT25 50" (Full HD 3D)
Polk Audio- Surround 7.1
Serving up my own 3D since 1996.
(34) Patents
-
Likay
- Petrif-Eyed
- Posts: 2913
- Joined: Sat Apr 07, 2007 4:34 pm
- Location: Sweden
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
My bad and a very poor formulated sentence. I do mean the distortion caused to a scene when converted to 2d+depth. The mention of depthinformation was meant as the in mind percieved image and i wrongfully called it depthinformation...BlackShark wrote:Actually no, 2D+depth contains more depth information than a stereo pair of pictures since it contains depth information for every single pixel.Likay wrote:2d+depth format can't be used as a format for true-3d capturing because important depthinformation will be lost..
Stereo pairs of pictures contain more 2D information in the areas that are occluded in one eye but visible in the other.
Very true. It's maybe a question of definition though. Until now my definition of true-3d is stereoscopy with two separate viewpoints, virtual or real. Maybe the only true-3d is entirely 3d-modelled scenes which can be rotated, cameras being moved around etc...Fredz wrote:True stereoscopy doesn't completely capture the geometry of a scene, it does only capture it for 2 viewpoints. When eye tracking displays like the AUO laptop will become more popular, we'll also see the limits of this technique when viewing 3D movies.Likay wrote:True stereoscopy (stereocamera with left+right image for instance) is true to the scene and it will capture it as it is
Nonethless your example clearly shows the limitations of "two viewpoint" stereoscopy. The explanation that a stereocamera will capture and reproduce the image as seen with eventual flaws of the display and present on a stereoscopic display is nonethless correct.
@cybereality: About movieconversions: Is it theoretically possible to maybe make an algorithm that turns a scene in a movie into a 3d-modelled scene by analysing the frames for movements, objects etc and by this information detect and make models for it. It's of course impossible to make entire full models but at least being able to detect everything of the models that's visible in the scene. Then replaying using a for the purpose "machinimaengine". Advantages should be the oppurtunity to change separation and convergence at least a little bit when replaying. Converting an already made stereomovie would provide even more information and should give better oppurtunities to change the stereo to own taste. I'm just brainstorming and maybe someone already tried this approach. Nonethless the task is probably greatly grayhairinducing...
One pixel surely isn't noticeable in most cases. 3d wouldn't be noticeable either....Chiefwinston wrote:BlackShark you are correct, depending on resolution and scaling that the displacement mapping is done at. This could be reduced to less than 1 pixel. Making it more or less irrelevant for gaming.
cheers
Mb: Asus P5W DH Deluxe
Cpu: C2D E6600
Gb: Nvidia 7900GT + 8800GTX
3D:100" passive projector polarized setup + 22" IZ3D
Cpu: C2D E6600
Gb: Nvidia 7900GT + 8800GTX
3D:100" passive projector polarized setup + 22" IZ3D
-
BlackShark
- Certif-Eyable!
- Posts: 1156
- Joined: Sat Dec 22, 2007 3:38 am
- Location: Montpellier, France
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
The less than one pixel case depends greatly on the object size and position, the troublesome issue is that when the diference becomes more than one pixel, it's because the object is drawn right under your nose : it's when the object is the most visible and attracting the viewer's attention that the difference is the greatest.Likay wrote:One pixel surely isn't noticeable in most cases. 3d wouldn't be noticeable either....Chiefwinston wrote:BlackShark you are correct, depending on resolution and scaling that the displacement mapping is done at. This could be reduced to less than 1 pixel. Making it more or less irrelevant for gaming.
cheers
Then, even in the 1 pixel case, the visibility of the problem depends on the size of the pixel on screen, the amount of these 1 pixel issues on screen and how wrong the colour of these pixels are computed relative to what they should be.
It could be well hidden as well as just as obvious as the nose in the middle of the face.
Passive 3D forever !
DIY polarised dual-projector setup :
2x Epson EH-TW3500 (2D 1080p)
Xtrem Screen Daylight 2.0, for polarized 3D
3D Vision gaming with signal converter : VNS Geobox 501
DIY polarised dual-projector setup :
2x Epson EH-TW3500 (2D 1080p)
Xtrem Screen Daylight 2.0, for polarized 3D
3D Vision gaming with signal converter : VNS Geobox 501
-
Fredz
- Petrif-Eyed
- Posts: 2255
- Joined: Sat Jan 09, 2010 2:06 pm
- Location: Perpignan, France
- Contact:
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
It was Euclid in -280 in his "Optica" treaty.BlackShark wrote:The difference may be more or less noticeable, but it's always mathematically there. One of the Greek mathematicians found that, I don't remember which one.
There are other problems preventing stereoscopy from being a "true 3D" technique, even if the viewer has the same exact characteristics than the cameras used to film the scene (position, orientation, interaxial distance, etc.).Likay wrote:Until now my definition of true-3d is stereoscopy with two separate viewpoints, virtual or real. Maybe the only true-3d is entirely 3d-modelled scenes which can be rotated, cameras being moved around etc...
In the reality, all the points you are looking at can be at different distances. So when you focus on a point, other visible points that are closer or farther to you will look blurred because of accommodation with the lens. The brain does use this cue to estimate the depth, but that can't be the case in stereoscopy where all the points will be in focus because they lie on the same plane (the screen).
For example, in this photo you can infer the size of the scene only with the blur effect :

The only way to simulate this in stereoscopy is to use depth of field techniques, but then you won't be able to focus on blurred zone of the screen, which was the case in some scenes in Avatar for example. And you would need really fast eye tracking to simulate real time depth of field on a PC, depending on where the viewer is looking at.
This is even more problematic when associated with the vergence of the eyes. It's been showed that when there is more than a 0,3 diopters difference between the distances of accommodation and convergence (6" max pop-out at a 30" viewing distance), there is a vergence-accommodation conflict which causes discomfort and visual fatigue.
So stereoscopy can't really be qualified as a "true 3D" technique. I think only holography can be called true 3D, but only in a limited form for now (no animation, technically limited depth).
It's been the subject of the "structure from motion" research based on the epipolar geometry, with an extensive research effort in the past three decades (eight-point algorithm in 1981 by Longuet-Higgins). The first important result in this field even dates back from the the 19th century (seven-point algorithm given by Chasles in 1855 and solved by Hesse in 1863).Likay wrote:Is it theoretically possible to maybe make an algorithm that turns a scene in a movie into a 3d-modelled scene by analysing the frames for movements, objects etc and by this information detect and make models for it. It's of course impossible to make entire full models but at least being able to detect everything of the models that's visible in the scene. Then replaying using a for the purpose "machinimaengine". Advantages should be the oppurtunity to change separation and convergence at least a little bit when replaying. Converting an already made stereomovie would provide even more information and should give better oppurtunities to change the stereo to own taste. I'm just brainstorming and maybe someone already tried this approach. Nonethless the task is probably greatly grayhairinducing...
The examples I gave links for about automatic depth estimation from cameras show some of the results that can be currently obtained in this field. There is also an evaluation initiative about stereo reconstruction algorithms that is equivalent to the depth estimation evaluation I presented before :
http://vision.middlebury.edu/mview/eval/" onclick="window.open(this.href);return false;
But we are still quite far from seeing an industrial implementation. It's a very interesting and promising field though, these techniques could surely be used for automatic 2D-3D conversion and new views synthesis in the future.
Last edited by Fredz on Mon Nov 22, 2010 10:01 pm, edited 1 time in total.
-
Chiefwinston
- Diamond Eyed Freakazoid!
- Posts: 712
- Joined: Fri Jun 19, 2009 8:05 pm
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
hmmm, thanks for the pictures and links Fredz. The abstract nature of a flat plane with viewable volume is endlessly facsinating to me. Your links made me think of the possibility of a reverse depth map from a viewers eyeballs to an object . One for the right eye one for the left eye. I'm only speculating here guys. But this reverse depth mapping (2) of them. This could in theory add a angular component for each pixel. I guess I'm trying to say is don't always conceptulize the depth map as strictly an in out on a coordinate system. Think of the possibilities of starting from a point- which adds angular info. Kinda helps with the creation of your stereo images from one picture.
cheers
cheers
AMD HD3D
i7
DDD
PS3
Panasonic Plasma VT25 50" (Full HD 3D)
Polk Audio- Surround 7.1
Serving up my own 3D since 1996.
(34) Patents
i7
DDD
PS3
Panasonic Plasma VT25 50" (Full HD 3D)
Polk Audio- Surround 7.1
Serving up my own 3D since 1996.
(34) Patents
-
Fredz
- Petrif-Eyed
- Posts: 2255
- Joined: Sat Jan 09, 2010 2:06 pm
- Location: Perpignan, France
- Contact:
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
I'm not sure I follow you, depth maps are already calculated this way. The Z-buffer value is calculated from the viewer position for each pixel on the screen, depending on the distance of objects.
-
Chiefwinston
- Diamond Eyed Freakazoid!
- Posts: 712
- Joined: Fri Jun 19, 2009 8:05 pm
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
Sorry Fredz, theres a mountian of z data. I'm trying to speculate as to what method will result in the best synthetic stereo pair. Obviously we would like there to be no visible difference when compared to a brute force generated stereo pair. We would also like adjustments in seperation and convergence- probably z data manipulation. I'm guessing that the 2D info would be in raster format for a game engine. But what if it were in vector format. The z data would have a very different and interesting relationship to a vector image and to the synthetic stereo pair. I'm only day dreaming here Fredz. So don't take it as anything but speculation and what ifs.
cheers
cheers
AMD HD3D
i7
DDD
PS3
Panasonic Plasma VT25 50" (Full HD 3D)
Polk Audio- Surround 7.1
Serving up my own 3D since 1996.
(34) Patents
i7
DDD
PS3
Panasonic Plasma VT25 50" (Full HD 3D)
Polk Audio- Surround 7.1
Serving up my own 3D since 1996.
(34) Patents
-
Chiefwinston
- Diamond Eyed Freakazoid!
- Posts: 712
- Joined: Fri Jun 19, 2009 8:05 pm
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
Its the resolution of vector graphics that kinda catch my attention. I've also taken my Crysis 2 3D video and freeze framed it. It looks like there using masking and composites in a fashion like I described earlier. But then agian the 3D isn't as impressive as the brute force method. Nothing comes off the screen. It's all inside the box 3D. With some of it having a very weak 3d effect at that. It doesn't look like we'll be ducking to get out f the way of stuff. I wouldn't give it a failing grade by any means though. Any one know of a release date.
cheers
cheers
AMD HD3D
i7
DDD
PS3
Panasonic Plasma VT25 50" (Full HD 3D)
Polk Audio- Surround 7.1
Serving up my own 3D since 1996.
(34) Patents
i7
DDD
PS3
Panasonic Plasma VT25 50" (Full HD 3D)
Polk Audio- Surround 7.1
Serving up my own 3D since 1996.
(34) Patents
-
skrubol
- Two Eyed Hopeful
- Posts: 98
- Joined: Wed Nov 05, 2008 12:47 pm
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
I can see how 2d+depth could be valuable in accelerating rendering. Render eye1, use z-buffer data to offset pixels for eye2 (leaving 'blank' pixels where there is no data.) rerender only blank pixels.
I'm guessing it's that last part that's the challenge today, rerendering just a small portion of a scene is probably not very computationally efficient (ie no different than rerendering the entire scene.) I think that this method might work well for ray tracing (as long as everything is matte and opaque,) as it kind of works backwards (rays go from the camera to the object rather than the reverse.)
Actually, thinking about raytracing makes me realize that this technique can never be 100% accurate, as every object has to be reflective (or else it is black,) and the effect of light sources at different angles will affect highlights, etc.
I'm going to have to read more on Z-buffering, occulsion, etc. Seems interesting stuff.
I'm guessing it's that last part that's the challenge today, rerendering just a small portion of a scene is probably not very computationally efficient (ie no different than rerendering the entire scene.) I think that this method might work well for ray tracing (as long as everything is matte and opaque,) as it kind of works backwards (rays go from the camera to the object rather than the reverse.)
Actually, thinking about raytracing makes me realize that this technique can never be 100% accurate, as every object has to be reflective (or else it is black,) and the effect of light sources at different angles will affect highlights, etc.
I'm going to have to read more on Z-buffering, occulsion, etc. Seems interesting stuff.
-
cybereality
- 3D Angel Eyes (Moderator)
- Posts: 11407
- Joined: Sat Apr 12, 2008 8:18 pm
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
Vectors have no resolution, they are resolution independent (or rather potentially infinite). However, in order to see a vector image on a conventional display it must be rasterized into pixel data. So you can never actually see a vector (expect on a special vector display, like they used on the Asteriods arcade, for example). I think vector 3D graphics can be really cool, but it doesn't seem like there is much interest in this field. I mean, for pre-rendered stuff you can do it (ie NURBs, etc.) but I don't know of any real-time engines that support this.Chiefwinston wrote:Its the resolution of vector graphics that kinda catch my attention.
-
Fredz
- Petrif-Eyed
- Posts: 2255
- Joined: Sat Jan 09, 2010 2:06 pm
- Location: Perpignan, France
- Contact:
Re: Kinect Inadvertently Demonstrates 3D, U-Decide Update
Yes, in the general case trying to render only the missing pixels would be quite equivalent to a complete scene re-render performance-wise, but I think it can be made more efficient by having a direct access to the engine. It won't resolve the illumination problem for pixels that are visible from both viewpoints though as you said, but I guess we can live with that better than with "warped" pixels on the edges.skrubol wrote:I'm guessing it's that last part that's the challenge today, rerendering just a small portion of a scene is probably not very computationally efficient (ie no different than rerendering the entire scene.)
Another approach could work in an equivalent way as what is done today, but with somewhat improved results I think. For now the general approach is to interpolate the color and depth in missing pixels from the information available for the foreground and the background. But we could estimate the depth of the background when there are depth discontinuties and use it to fill the missing pixels by only interpolating the background pixel colors.

I think that would give better results than what Virtual 3D shows in the screenshots from Cybereality, especially on the edges of the boxes where there is only the sky or the floor behind. These zones wouldn't look warped anymore, especially at the corners of the boxes. It would still miss objects that lie in the unknown zones though, so there should be other artefacts like small objects or edges popping out from time to time.